Turning to the web for information is so commonplace that not many people give much thought to how important data is for personal or business use or how it is obtained.
Researchers, students and marketing personnel need information on a regular basis. Others may access the web occasionally. People may be looking to buy products or make travel arrangements or search for institutions. In such cases the most common method of getting information is through the manual process. In this method users navigate to each page and look for specific bits of information. They then copy-paste the information or save the entire webpage. This is a laborious and long drawn out process, which is also inefficient but works for the occasional user. The advantage is that users need not install any software or learn scripting or do anything other than copy-paste. The disadvantage is that it is time consuming. More, in this method people come up against websites that restrict access to data.
The second method is for people with a degree of familiarity with computer scripting and coding. Those familiar with Java, ASP or Perl can come up with scripts that will help them pull data from websites. Programmers can set up scripts to analyze contents of HTML pages and selectively segregate data of interest to them. This is a rather raw method and works fine for people with a degree of expertise in scripting. The advantage is that most programming languages have a common syntax and one script can do the trick. The disadvantage is that it requires a fair bit of knowledge to make it work. If contents of a website change then programmers have to do the scripting all over again. In this approach one still needs to navigate pages.
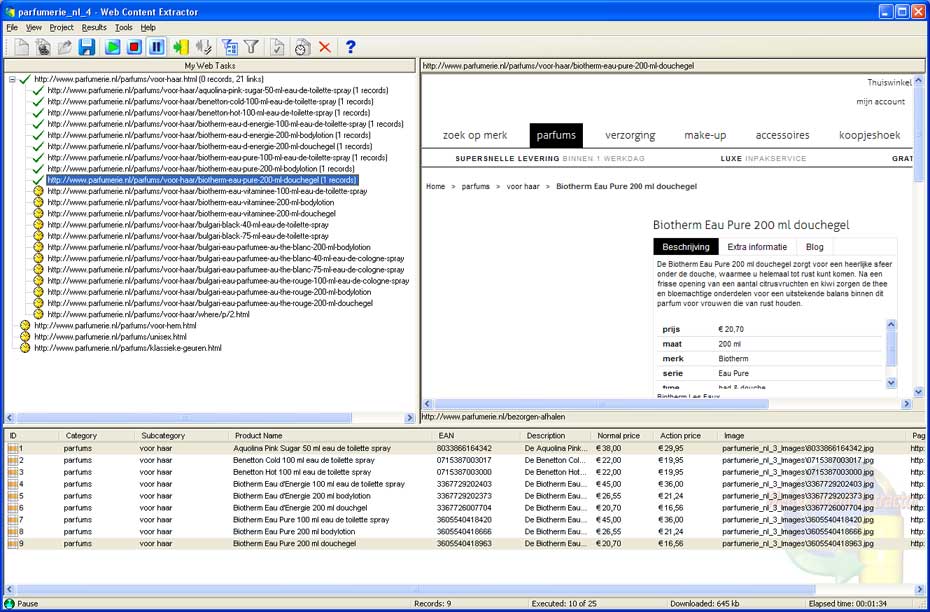
The third method is the simplest and easiest of all. One simply downloads and installs web data extraction software that includes a bit of artificial intelligence and a fair amount of programming to make it easy, even for novices, to get quality data from thousands of websites in an automated process. Even those familiar with computer programming benefit by using this automated extraction software to get data from complex websites with a degree of copy protection. This is what an automated web data extractor will do:
It has an easy to use interface with additional command line options. Novices can use the menu system and enter URLs and keywords. Advanced users can input filters and other parameters in the command line options for even more refined results.
The web data extraction software works in multi-threaded mode, accessing about 20 URLs simultaneously and does it all unattended.
Users specify the type of data format required and the software automatically filters out all extraneous text and simply presents data in the required format for immediate use.
Users can schedule the data extraction process and thus distribute load on their internet connection.
The extractor works through proxy servers and rotates IP addresses automatically. This is of great use when it comes up against websites that require log in or have some monitoring methods to detect frequent attempts to download data.
Automated software, the third option, is the best in terms of time, labor and money savings and should be the default choice for everyone and anyone who needs to get information from the web.
 RSS Feed
RSS Feed